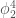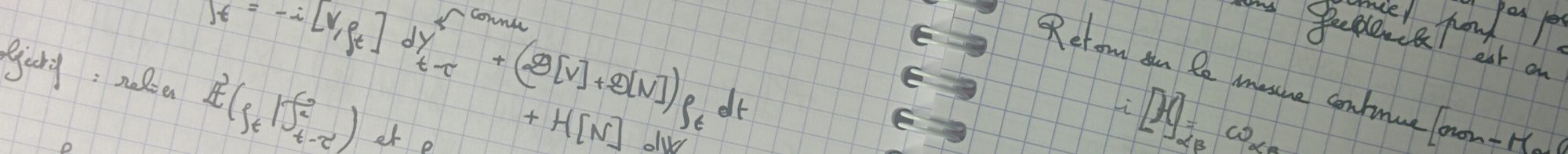
There are 2 recent preprints on tensor networks I found interesting.
The first is Collective Monte Carlo updates through tensor network renormalization (arxiv:2104.13264) by Miguel Frias-Perez, Michael Marien, David Perez Garcia, Mari Carmen Banuls and Sofyan Iblisdir. I am certainly a bit biased because two authors come from our group at MPQ, and I heard about the result twice in seminars, but I think it is a genuinely new and interesting use of tensor networks. The main idea is to reduce the rejection rate of Markov Chain Monte Carlo (MCMC) by crudely estimating the probability distribution to be sampled from with tensor network renormalization. This combines the advantage of the Monte Carlo method (it is exact asymptotically, but slow especially for frustrated systems) with the advantage of tensor renormalization (it is very fast for approximations).

A quick word of caution for purists, technically they use the tensor renormalization group (TRG), which is the simplest approximate contraction method for 2d tensor networks. Tensor network renormalization (TNR) can refer to a specific (and more subtle) renormalization method introduced by Evenbly and Vidal (arxiv:1412.0732) that is in fact closer to what the Wilsonian RG does. This is just a matter of terminology.
Terminology aside, it seems the hybrid Monte Carlo method they obtain is dramatically faster than standard algorithms, at least in number of steps to thermalize the Markov chain (which remains of order 1 even for reasonably low bond dimensions). These steps are however necessarily more costly than for typical methods because sampling from the approximate distribution generated with TRG gets increasingly expensive as the bond dimension increases. As a result, for a large frustrated system, it is not clear to me how much faster the method can be in true computing time. I think in the future it would be really interesting to have a benchmark to see if the method can crush the most competitive Markov chain heuristics on genuine hard problems, like spin glasses or hard spheres for example. It is known that TRG struggles to get precise results for such frustrated problems, and so the approximation will surely degrade. But perhaps there is a sweet spot where the crude approximation with TRG (of high but manageable bond dimension) is sufficient to have a rejection rate in the MCMC at 10^(-4) instead of 10^(-15) for other methods in a hard-to-sample phase.
The second one is Entanglement scaling for 

So far, the most efficient method is to discretize the model, use the most powerful lattice tensor techniques to solve it, and then extrapolate the results to the continuum limit. The extrapolation step is crucial. Indeed, such relativistic field theories are free conformal field theories at short distance. This implies that for a fixed error, the bond dimension of the tensor representation (and thus the computational cost) explodes as the lattice spacing goes to zero. One can take the lattice spacing small, but not arbitrarily small.
With Clément Delcamp, we explored this strategy in the most naive way. We had used a very powerful and to some extent subtle algorithm (tensor network renormalization with graph independent local truncation, aka GILT-TNR) to solve the lattice theory. We pushed the bond dimension to the max that could run on our cluster, plotted 10 points and extrapolated. At the smallest lattice spacing, we were already very close to the real continuum theory, and a fairly easy 1-dimensional fit with 3 parameters gave us accurate continuum limit results. A crucial parameter for 

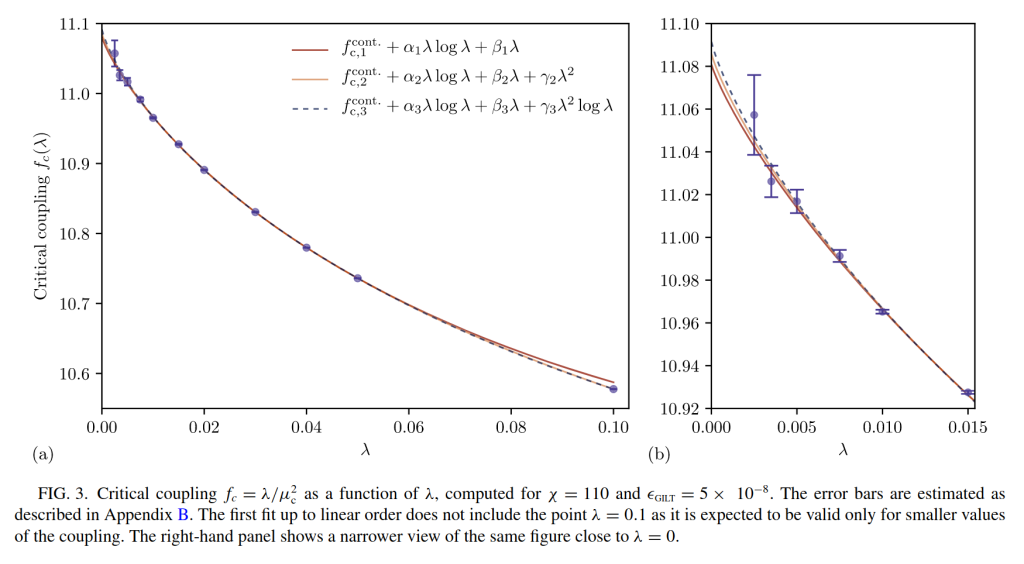
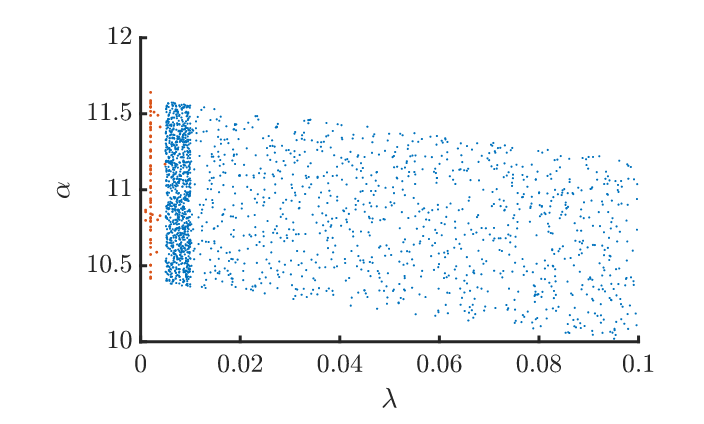
Bram Vanhecke and collaborators follow a philosophically different strategy. They use an arguably simpler method to solve the lattice theory, boundary matrix product states. Compared to GILT-TNR, this method is simpler but a priori less efficient to solve an exactly critical problem. But, spoiler, they ultimately get better estimates of the critical coupling than we did. How is that possible? Instead of simulating exactly the critical theory with the highest possible bond dimensions, the authors simulate many points away from criticality and with different bond dimension (see image below). Then they use an hypothesis about how the results should scale as a function of the bond dimension and distance from criticality. This allows them to fit the whole theory manifold around the critical point without ever simulating it. This approach is much more data driven in a way. It swallows the bullet that some form of extrapolation is going to be needed anyway and turns it into an advantage. Since the extrapolation is done with respect to more parameters (not just lattice spacing), the whole manifold of models is fitted instead of simply a critical line. This gives the fit more rigidity. By putting sufficiently many points, which are cheap to get since they are not exactly at criticality or with maximal D, one can get high precision estimates. They find 
Naturally, an extrapolation is only as good as the hypothesis one has for the functional form of the fit. There, I like to hope that our earlier paper with Clément helped. By looking at the critical scaling as a function of the lattice spacing, and going closer to the continuum limit than before, we could see that the best fit clearly contained logarithms and was not just a very high order polynomial (see above). I think it was the first time one could be 100 % sure that such non-obvious log corrections existed (previous Monte Carlo papers had ruled it out after suspecting it), the 
Could this scaling have been found theoretically? Perhaps. In this new paper, Vanhecke and collaborators provide a perturbative justification. My understanding (which may be updated) is that such a derivation is only a hint of the functional form because the critical point is deep in the non-perturbative regime and thus all diagrams contribute with a comparable weight. For example, individual log contributions from infinitely many diagrams could get re-summed into polynomial ones, e.g. 
In the end, congratulations to Bram, Frank, and Karel for holding the critical