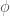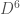Today I put online a major update of my pair of papers on the variational method for quantum field theory (short here, long here). The idea is still to use the same class of variational wave functions (relativistic continuous matrix product states) to find the ground state of (so far bosonic) quantum field theories in 1+1 dimensions. The novelty comes from the algorithm I now use to compute expectation values, that has a cost only proportional to where is the bond dimension. Using backpropagation techniques, the cost of computing the gradient of observables with respect to the parameters is also only . This is basically the same asymptotic scaling as standard continuous matrix product states.
Previously, the method was a nice theoretical advance as it worked without any cutoff, but it was not numerically competitive compared to bruteforce discretization + standard tensor methods (at least not competitive for most observables insensitive to the UV). With the new algorithm with improved scaling, I can go fairly easily from to , which gives relative error for the renormalized energy density at a coupling of order 1. Crucially, the error really seems to decrease exponentially as a function of the bond dimension, and thus with only a slightly higher numerical effort (say 100 times more) one could probably get close to machine precision. Already at relative error for the renormalized energy density, that is a quantity where the leading lattice contribution has been subtracted, I doubt methods relying on a discretization can compete. This makes me a bit more confident that methods working directly in the continuum are a promising way forward even if only for numerics.
Energy density and relative error for theory with RCMPS. RHT is the state-of-the-art renormalized Hamiltonian truncation result which is manifestly less precise
Now, let me go a bit more into the technicalities. Computing expectation values of local functions of the field with such a low cost seems difficult at first because the ansatz is not written in terms of local functions of . Naively this should at the very least square the cost to . The main idea to obtain the cheap scaling is to realize that the expectation value of vertex operators, i.e. operators of the form , can be computed by solving an ordinary differential equation (ODE) where the generator has a cost . Basically, computing vertex operators for relativistic CMPS is as expensive as computing field expectation values for standard non-translation-invariant CMPS. To solve this ODE, one can use powerful method with extremely quickly decaying errors as a function of the discretization step (e.g. very high order Runge-Kutta). So vertex operators are, in fact cheap. But local powers of the field are merely differentials of vertex operators, and thus can be computed as well for the same cost. Finally, to get the gradient, one can differentiate through the ODE with backpropagation, and obtain the result for only twice the cost. This allows the full variational optimization for all well-defined bosonic Hamiltonians with polynomial and exponential potentials.


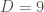
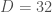

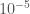

 theory with RCMPS. RHT is the state-of-the-art renormalized Hamiltonian truncation result which is manifestly less precise
theory with RCMPS. RHT is the state-of-the-art renormalized Hamiltonian truncation result which is manifestly less precise