Recently, a study carried out partly by INSERM researchers on endocrine disruptors has been discussed quite a lot in French mainstream medias (see for example in le Monde, France Inter, le Point, le Parisien, Libération). The conclusion of the study is allegedly the following: young kids whose mother has been exposed to certain phenols and phtalates have an increased risk to develop behavioral disorders (such as hyperactivity). Such a conclusion, if it were really robustly supported by the study, would no doubt deserve a wide coverage. Unfortunately (or fortunately) that does not seem to be the case. After reading the study, it seems to me that if an adverse effect exists, it is sufficiently small to be statistically insignificant on a sample of more than 500 people.
Before jumping in the details and criticizing the publicity around a statistically under-powered study, let me provide a disclaimer. I am neither a biologist nor a medical doctor. I have no specific knowledge of the mechanisms by which phtalates and phenols may adversely impact the human body. It is entirely possible that these compounds indeed have a damaging effect on humans at a large scale, something the rest of the literature suggests. My objective is also not to discuss the experimental aspects of the test protocol of the study (urine samples, survey, etc.), I am not qualified to do so. I would just like to discuss the statistical part that illustrates a recurring difficulty in epidemiology and psychology. It is also an excuse to think about the mainstream reporting of such discoveries.
The study

Let me introduce briefly the study. The objective of the authors was to see if chemicals of the family of phenols and phtalates had adverse effects on the behavior of young boys. They used a urine sample from the mother as a proxy to the fetus’ exposition in utero and two surveys (answered by the mother) as proxies to the boy’s behaviors at 3 and 5 years. The number of participants ranged from 529 to 464 at the end of the study. According to the abstract, they found that Bisphenol A (BPA) was responsible for relationship problems at age 3 and hyperactivity-inattention problems at age 5. Three other compounds (Mono-n-butyl phtalates, Monobenzyl phtalaten, and triclosan) were also found to have the same kind of adverse effects on various behavioral subtests.

These results all seem statistically significant and are presented as such. So it looks like the news are accurate. Reading the main text however gives a different message. To understand why, we need to make a detour by elementary statistics.
The objective of the study is to see if there exists a correlation (hinting at a causation in this context) between exposition to some compounds and behavior. The difficulty is that behavioral problems may happen to all kids, whether or not they have been exposed to endocrine disruptors. To simplify, we can imagine that there are two groups of equal size, one that has been exposed and one that has not. Because there will be kids with behavioral problems in both groups, it may happen that the difference of observed rate measured in the two groups is just the result of chance. Tossing a coin 100 times may give 55 heads and 45 tails even if the coin is not biased, just out of “typical” randomness. We can never be sure that a result is not just a statistical fluke. What we can do however, is quantify the probability that the result would have happened had it been produced by randomness. We can ask: what is the probability p that we would have found the observed ratio of kids with problems in each group, had the two groups been the same? The definition of this probability may look convoluted but one should be careful to not simplify it into “What is the probability that there is an effect?”. This latter probability is impossible to know without additional assumptions.
The threshold for the probability p is often put at 5%. Usually one says a result is statistically significant if the data is such that chance would have produced it in less than 5% of the cases. The results found in the abstract of the study and mentioned before all meet this threshold. They thus look quite robust according to the standards in the field. But they are not.
Fake discovery rate or “look elsewhere effect”
Let us go back to the coin toss example. Let us say I have tossed a coin 100 times and I find 65 heads and 35 tails. The probability that a fair coin gives more than 65 heads is less than 5%. So I would tend to say that my coin is biased. Let us now say that I have 1000 different coins. I throw the first one, I get say 55 heads 45 tails. Maybe it’s unbiased. So I throw the next one, and the next one, and the next one… At some point, say at the 258th coin, I find 65 heads and 35 tails. Does that mean the coin is biased? Taken alone, this result looks statistically significant. Considering the experiment as a whole, it could have totally happened by chance. It is likely that something unlikely happens if it is attempted many times. In that case, unless I get the opportunity to test the 258th coin again, I cannot say much.
So if we test many hypothesis at the same time, we are sure that some will look independently statistically significant. If this is not taken care of, there is an important risk of fake discovery. This is a very well known problem in epidemiology and in psychology. Most researchers now correct their results of statistical significance taking into account the many hypothesis they have explored. Sometimes however, this is difficult because the hypothesis that were tested but gave null results are simply not published or not ever remembered if they were only briefly considered. This difficulty is at the root of the replication crisis in psychology where many historically important results cannot be reproduced and are now understood to have been the result of pure chance.
In particle physics, experimentalists face a similar problem. To look for new particles, they check if the signal they measure can be explained by the random background of known physics. But because they have many signals, at different energies, and in different production channels, they are effectively testing many hypothesis and so they have to be careful not to trust weakly locally significant results. To avoid fake discoveries, the threshold p, the probability that the background would have given such a result, is traditionally pushed to an absurdly small value of 5 sigma (i.e. 
Back to the study
The study we are interested in is very transparent about what hypothesis have been tested and is extremely precise from that point of view. The authors are models of rigor. The results are summarized in 4 tables that are similar and only differ in some minor subtleties (test at 3 or 5 years) and in the way statistical corrections are applied. The first one is shown below as an illustration:
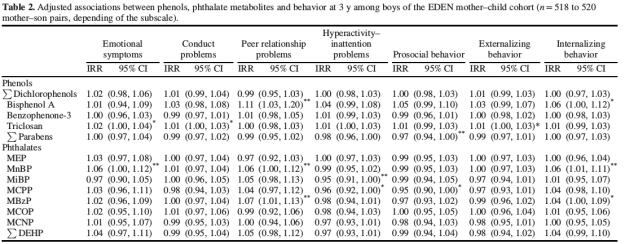
Two stars next to a number mean that it is individually statistically significant. For example, in the “Bisphenol A” line and “peer relationship problems” column we have a number larger than 1 (which means positive correlation here) and two stars, meaning that the result is statistically significant (p < 5%). But considering the table immediately points to the previous difficulty. The authors have measured the correlation between 15 compounds and 7 behavioral subtests, that is a total of 105 hypothesis. For 7 of them, the authors find a statistically significant effect, which is typically what one would obtain… from pure chance, as in the coin tossing example. Interestingly, the MiBP is even found to reduce hyperactivity problems! This is not surprising and easily attributed to the testing of too many hypotheses with a low significance threshold. But if one rightfully finds the positive effect of MiBP likely spurious, one is bound to conclude that it could as well be the case for the negative effects reported.
In the main text, the authors are perfectly honest and acknowledge the fact that the results considered as a whole are not statistically significant.
“When we applied a correction for multiple comparisons using an FDR [fake discovery rate] method, none of the associations reported in the results section remained significant, the lowest corrected p-value being 0.42 for the association between BPA and the peer relations problem score at 3y.”
As a result they later acknowledge that the results can be due to chance.
“Because we tested many associations, some of our results might be chance finding, as suggested by the fact that none of the observed p-values remained significant after FDR correction.”
The “might” might be a bit too weak given that the results are far from being statistically significant globaly. The rest of the article is devoted to an interesting discussion of the previous literature that may go in the same direction as the results individually significant. This is aimed at providing a justification to “keep” them and mention them in the conclusion. This is indeed rational from a Bayesian point of view to give more credit to results if they confirm previous findings. Nonetheless, as the justification is likely found a posteriori in the literature, there is a strong risk of confirmation bias. I think in the present situation, the best one can honestly conclude is that the study does not explicitly contradicts the existing literature but does not allow one to reliably make a conclusion in one way or another. Perhaps there is one comforting robust result which is that the effect of the compounds tested, if it exists, is sufficiently small to remain statistically insignificant on a sample of 500 people. If endocrine disruptors are causing some behavioral troubles, this study would suggest that they are not the main cause.
One may wonder why the researchers tested so many hypothesis knowing it would likely ruin the statistical significance of their results. It is actually totally understandable. The authors had a unique and rare dataset, that took years to be collected. It is tempting to “make the best of it” and explore as many associations as possible. The drawback is that the study becomes only exploratory. Further studies are needed to rigorously assess the effects of each molecule individually. This is very standard but it is important to understand that one should not conclude anything and especially not base any public policy on exploratory studies (unless they find globally statistically significant results). Indeed, such studies will typically have a huge rate of false positives. The same study replacing the 15 molecules by 15 different varieties of carrots or potatoes would have typically found that 5 of them had individually statistically significant adverse effects on some behavioral trait. As I hope this illustrates, basing public policies on associations coming from such exploratory studies would not be the reasonable application of the precautionary principle, it would be pure insanity.
Who is to blame?
Given the important limitations of the study, the reporting around it was clearly excessive and people were given an inaccurate presentation of the results. Not a single one of the news articles I have seen alludes to the statistical weakness of the study. So who is to blame? Interestingly, I do not think that there is any major culprit in this situation, but rather a succession of small inefficiencies in modern science and in the way it is reported.
The authors of the study cannot easily be blamed. Their article is a marvel in academic writing: it is perfectly correct while subliminally implying a little bit more than it actually demonstrates. The abstract is factually correct and only “omits” the qualifiers that the findings are only locally statistically significant. But the authors might defend themselves arguing that all the limitations of a study cannot be mentioned in the abstract (otherwise, who would need the full study?). The editor or referees could have requested that the abstract not only display technically correct information but also do not mislead the public. This would have forced the authors to report a negative result. But after all, one can read the main text especially as the journal is open access.
In the present case, the journalists have most likely not even read the abstract of the article. Most of the mainstream articles were clearly reporting only what was written in the official press release from INSERM. The press release does not mention a single relevant limitation of the study. I think this is where a mistake was made. Journalists should never take a press release on recent scientific findings as the unique source for a piece. One can write anything in a press release. Even if INSERM is a respectable and reliable institution, its researchers are humans. They will naturally be tempted to inflate the impact of their results in a non peer reviewed release. Researchers need to secure funding, they want their students to be hired in the future, and they have an ego like everyone else.
It is natural for journalists to distrust press releases coming from companies like Monsanto and to cross-check everything that is written in them. It is natural and desirable: the company may present the findings in a biased way to push forward its agenda. But journalists should not entirely drop their skepticism when the research comes from public or independent research institutions. Again, researchers are almost always of good faith but they are humans.
Conclusion
Do low doses of phenols and phtalates have adverse effects on the health of young boys? From the study I discussed, I think it is impossible to know. This does not mean it is not the case. The effect may be subtle enough that the study I mentioned only spotted it in a statistically insignificant way. Research on larger populations may find a robust association in the future. Should one modify the regulation on phenols and phtalates based only on the study I discussed? I think not. If one takes seriously all the locally statistically significant adverse effects found in exploratory studies, one can forbid carrots, potatoes, or even water. This does not mean that there are no other studies telling us to tightly regulate phenols of phtalates. Unfortunately I do not know the literature well, but this review for example seems to point to unquestionable adverse effects of BPA, especially on reproductive functions. So there are probably good reasons to tightly regulate BPA. That said, pushing forward studies that are not really conclusive and thus easy to rebute is probably not the best way to get such a regulation in place.
