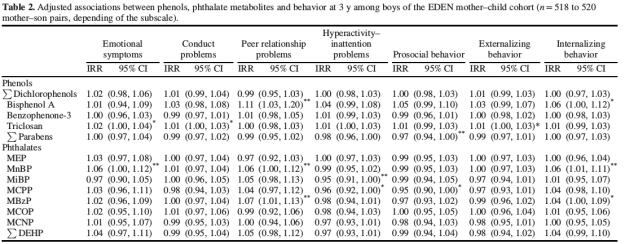
Survival Bias
During World War II, the US military did statistics to see where its bombers got primarily damaged. The pattern looked like the picture on the right. The first intuition of the engineers was to reinforce the parts that were hit the most. Abraham Wald, a statistician, realized that the distribution of impacts was observed only for the airplanes that actually came back from combat. Those that were hit somewhere else could probably not even make it back home. Hence it is precisely where the planes seemed to be the least damaged that adding reinforcements was the most useful! This famous story illustrates the problem of survival bias (or survivorship bias).
Definition (Wikipedia): Survival bias is the logical error of concentrating on the people or things that made it past some selection process and overlooking those that did not.
Survival bias is the reason why we tend to believe in planned obsolescence and more generally why we sometimes have the nostalgia of a golden age that never existed. “Back in the days, cars and refrigerators were reliable, unlike today! And back then, buildings were beautiful and lasted forever unlike the crap they construct today!”
But actually none of this is true. Most refrigerators from the sixties stopped working in a few years and the very few that still function today are just in the 0.1% that made it. The same goes for cars which are more reliable than they used to be: the vintage cars we see around show an impressive number of kilometers, but only because they are part of the infinitesimal fraction that miraculously survived. Finally, most buildings in earlier centuries were poorly constructed, lacking both taste and resistance. Most of them collapsed or got destroyed and this is why new buildings now stand in place of them. The few old monuments that remain are still there precisely because they were particularly beautiful and well constructed for the time. More generally, the remnants of the past we see in our everyday life are not a fair sample of what life used to be. They are, with rare exceptions, the only things that were good enough to not be replaced.
Survival bias can explain an impressively wide range of phenomena. For example, most Hedge Funds show stellar historical returns (even after fees) while investing in hedge funds is not profitable on average. This is easy to understand if hedge funds simply have random returns: the hedge funds that lose money after a period go bankrupt or have to downsize for lack of investors while hedge funds that made money survive and increase in size. The same bias explains why the tech success stories are often overrated and why it seems cats do not get more injured when they fall from a higher altitude (wikipedia).
This bias very often misleads us in our daily life. My worry is that it may also mislead us in our assessment of physical theories, especially when we lack experimental data. To understand why, I need to discuss the problem of the “non-empirical confirmation” of physical theories.
Non-empirical confirmation of physical theories
Physicists always use some form of non-empirical assessment of physical theories. Most theories never get the chance to be explicitly falsified experimentally and are just abandoned for non-empirical reasons: it is just impossible to make computations with them or they turn out to violate principles we thought should be universal. As the time between the invention of new physical theories and their possible experimental test widens, it becomes important to know more precisely what non-empirical reasons we use to temporarily trust theories. The current situation of String Theory, which predicts new physics that seems untestable in the foreseeable future, is a prime example of this need.
This is a legitimate question that motivated a conference in Munich about two years ago “Why trust a theory? Reconsidering scientific methodology in light of modern physics“, which was then actively discussed and reported on online (see e.g. Massimo Pigliucci, Peter Woit and Sabine Hossenfelder). Among the speakers was philosopher Richard Dawid, who has come up with a theory (or formalization) of non-empirical confirmation in Physics, notably in the book String Theory and the Scientific Method.
Dawid contends that physicists so far use primarily the following criteria to assess physical theories in the absence of empirical confirmation:
- Elegance and beauty,
- Gut feelings (or the gut feelings of famous people),
- Mathematical fertility.
I think Dawid is unfortunately correct in this first analysis. The reasons why physicists momentarily trust theories before they can be empirically probed are largely subjective and sociological. This anecdote recalled by Alain Connes in an interview about 10 years ago is quite telling:
“How can it be that you attended the same talk in Chicago and you left before the end and now you really liked it. The guy was not a beginner and was in his forties, his answer was ‘Witten was seen reading your book in the library in Princeton’.”
Note that this does not mean that science is a mere social construct: this subjectivity only affects the transient regime when “anything goes”, before theories can be practically killed or vindicated by facts. Yet, it means there is at least room for improvement in this transient theory building phase.
Dawid puts forward 3 principles, which I will detail below, to more rigorously ground the assessment of physical theories in the absence of experimental data. Before going any further I have to clarify what we may expect from non-empirical confirmation. There is a weak form: we mean by non-empirical confirmation simply a small improvement in the fuzzily defined Bayesian prior we have that a theory will turn out to be correct. This is the uncontroversial understanding of non-empirical confirmation, but one that Dawid deems too weak. There is also a strong form, where “confirmation” is understood in its non-technical sense, that of definitely validating the theory without even requiring experimental evidence. This one, which some high energy theorists might sometimes foolishly defend, is manifestly too strong. Part of the controversy around non-empirical confirmation is that Dawid wants something stronger than the weak form (which would be trivial in his opinion) but weaker than the strong form (which would be simply wrong). However, because it is quite difficult to understand precisely where this sweet spot would lie, Dawid has often been caricatured as defending an unacceptably strong form of his theory.
What we may expect from non-empirical hints is an important question and I will come back to it later. Right now, I ask: can we find good guides to increase our chances to stay on the right track whilst experiments are still out of reach?
Dawid’s principles
- No Alternative Argument (aka “only game in town”):
Physicists tried hard to find alternatives, they did not succeed.

- Meta-Inductive Argument:
Theories with the same characteristics (obeying the same heuristic principles) proved successful in the past.
- Unexpected Explanatory Interconnections:
The theory was developed to solve a problem but surprisingly solves other problems it was not meant to.
These principles are manifestly crafted with String Theory in mind for which they seem to fit perfectly. String Theory is not the only game in town but it is arguably more developed than the alternatives (and arguably more developed than some alternatives I find interesting). String Theory also fares well on the Meta Inductive Argument: it uses extensively the ideas and principles that made the success of previous theories, especially those of quantum field theory. In the course of the development of String Theory, a lot of unexpected interconnections also emerged. Many of them are internal to the theory: different formulations of String Theory actually seem to describe different limits of the same thing. But there are also unexpected byproducts: e.g. a theory constructed to deal with the strong nuclear force ends up containing gravitational physics.
At this stage, one may be tempted to nitpick and find good reasons why String Theory does not actually satisfy Dawid’s principles, possibly to defend one’s alternative theory. However, I am not sure this is a good line of defense and think it draws the attention away from the interesting question: independently of String Theory, are Dawid’s principles a good way to get closer to the truth?
Naive meta check
We may do a first meta check of Dawid’s principle, i.e. ask the question:
Would these principles have worked in the past?
or
Would they have guided us to what we now know are viable theories?
We may carry this meta check on the Standard Model of particle physics (an instance of Quantum Field Theory) and General Relativity.
At first sight, both theories fare pretty well. It seems that quantum field theory quickly became the main tool to describe fundamental particles while being the simplest extension of the principles that were previously successful (quantum mechanics and special relativity). Further, quantum field theoretic techniques unexpectedly applied to a wide range of problems including classical statistical mechanics. General relativity also seemed like it was the only game in town, minimally extending the earlier principles of special relativity introduced by Einstein. The question of the origins of the universe, which General Relativity did not primarily aim to answer, was also unexpectedly brought from metaphysics to the realm of physics. I chose simple examples, but it seems that for these two theories, there are plenty of details which fit into the 3 guiding principles proposed by Dawid. The latter look almost tailored to get the maximum number of points in the meta check game.
Fooled by survival bias
As convincing as it may seem, the previous meta check is essentially useless. It shows that successful theories indeed fit Dawid’s principles. But we have looked only at the very small subset of successful theories. It does not tell thus that following the principles would have led us to successful theories rather than unsuccessful ones. In the previous assessment, we were being dangerously fooled by survival bias. We looked at the path ultimately taken in the tree of possibilities, focusing on its characteristics, but forgetting that what matters is rather the difference with other possible paths.
To really meta check Dawid’s principles, it is important to study failures as well: the theories that looked promising but then were disproved and ultimately forgotten. For obvious reasons, such theories are no longer taught thus all too easy to overlook.
A brief History of failures
Let us start our brief History of promising-theories-that-failed by Nordström’s gravity. This theory is slightly anterior to General Relativity and was proposed by Gunnar Nordström in 1913 (with crucial improvements by Einstein, Laue, and others; see Norton for its fascinating history). It is built upon the same fundamental principles as General Relativity and differs only subtly in its field equations. Mainly, General Relativity is a tensor theory of gravity, in that the Einstein’s tensor 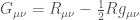 is proportional to the matter stress-energy tensor
is proportional to the matter stress-energy tensor 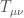 :
:

Nordström’s theory is a simpler scalar theory of gravity. The curvature  is sourced by the trace
is sourced by the trace  of the stress-energy tensor. This field equation is insufficient to fully fix the metric and one just adds the constraint that the Weyl tensor
of the stress-energy tensor. This field equation is insufficient to fully fix the metric and one just adds the constraint that the Weyl tensor 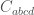 is zero:
is zero:

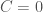
This makes Nordström’s theory arguably mathematically neater than Einstein’s theory. Further, while it brings all the modern features of metric theories of gravity, its prediction are in many cases quantitatively closer to the predictions of Newton’s theory. Finally, for two years, it was the only game in town as Einstein’s tensor theory was not yet finished.
But Nordström’s theory predicts no light deflection by gravitational fields and the wrong value (by a factor  ) for the advance of the perihelia of Mercury. These experimental results were not known in 1913. If we had had to compare Nordström’s and Einstein’s theories with Dawid’s principles, I think we would have hastily given Nordström the win.
) for the advance of the perihelia of Mercury. These experimental results were not known in 1913. If we had had to compare Nordström’s and Einstein’s theories with Dawid’s principles, I think we would have hastily given Nordström the win.
Another example of a promising theory that was ultimately falsified is the  Grand Unified theory, proposed by Georgi and Glashow in 1974. The idea is to embed the Gauge groups
Grand Unified theory, proposed by Georgi and Glashow in 1974. The idea is to embed the Gauge groups 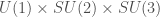 of the Standard Model into the simple Gauge group . In this theory, the 3 (non gravitational) forces are the low energy manifestations of a single force. Going towards greater unification had been a successful way to proceed, from Maxwell’s fusion of electric and magnetic phenomena to Glashow-Salam-Weinberg’s electroweak unification. Further, the introduction of a simple Gauge group mimics earlier approaches successfully applied to quarks and the strong interaction. The theory of Georgi and Glashow seems to leverage the unreasonable effectiveness of mathematics (coined by Wigner) in its purest form.
of the Standard Model into the simple Gauge group . In this theory, the 3 (non gravitational) forces are the low energy manifestations of a single force. Going towards greater unification had been a successful way to proceed, from Maxwell’s fusion of electric and magnetic phenomena to Glashow-Salam-Weinberg’s electroweak unification. Further, the introduction of a simple Gauge group mimics earlier approaches successfully applied to quarks and the strong interaction. The theory of Georgi and Glashow seems to leverage the unreasonable effectiveness of mathematics (coined by Wigner) in its purest form.
The Grand Unified Theory predicts that protons can decay and have a lifetime of  years. The Super-Kamiokande detector in Japan has looked for such events, without success: if protons actually decay, they do so at least a thousand times too rarely to be compatible with theory. Despite the early enthusiasm and its high score at the non-empirical confirmation game, this theory is now falsified.
years. The Super-Kamiokande detector in Japan has looked for such events, without success: if protons actually decay, they do so at least a thousand times too rarely to be compatible with theory. Despite the early enthusiasm and its high score at the non-empirical confirmation game, this theory is now falsified.
Physics is full of such examples of theoretically appealing yet empirically inadequate ideas. We may mention also Kaluza-Klein type theories unifying gauge theories and gravity, S-matrix approaches to the understanding of fundamental interactions, and Einstein’s and Schrödinger’s attempts at unified theories. We can probably add many supersymmetric extensions of the Standard Model to this list given the recent LHC null results. In many cases, we have theories that fit Dawid’s principles even better than our currently accepted theories, but that nonetheless fail experimental tests. The Standard Model and General Relativity do pretty well in the non-empirical confirmation game, but they would have been beaten by many alternative proposals. Only experiments allowed to choose the right yet not-so-beautiful path.
Conclusion
Looking at failed theories makes Dawid’s principles seem less powerful than a test on a surviving subset. But I do not have a proposal to improve on them. It may very well be that they are the best one can get: perhaps we just cannot expect too much from non-empirical principles. In the end, I am not sure we can defend more than the weakest meaning of non-empirical confirmation: a slight improvement of an anyway fuzzily defined Bayesian prior.
Looking at modern physics, we see an extremely biased sample of theories: they are the old fridge that is still miraculously working. Their success may very well be more contingent than we think.
I think this calls for more modesty and open-mindedness from theorists. In light of the historically mixed record of non-empirical confirmation principles, we should be careful not to put too much trust in neat but untested constructions and remain open to alternatives.
Theorists often behave like deluded zealots, putting an absurdly high level of trust in their models and the principles on which they are built. While it may be efficient to obtain funding, it is suboptimal to understand Nature. Theoretical physicists too can be fooled by survival bias.
This post is a write up of a talk I gave for an informal seminar at MPQ a few months ago. As main reference, I have used Dawid’s article The Significance of Non-Empirical Confirmation in Fundamental Physics (arXiv:1702.01133) which is Dawid’s contribution to the “Why trust a theory” conference.

 Anil’s writing style is very enjoyable. He does not make the all too common mistake of using cheap metaphors which are dangerous in the context of quantum mechanics where they provide a deceiving impression of depth and understanding. In this book, you actually learn something. Sure you do not become an expert in foundations, but you get an accurate sense of what motivates researchers in the field. This is both nice in itself, and if you want to keep on digging with a more specialized book. Even though I already knew the technical content of the book, I found the inquiry captivating. I definitely recommend Through two doors at once, especially to my friends and family who want to quickly yet genuinely understand the sorts of questions that drive me.
Anil’s writing style is very enjoyable. He does not make the all too common mistake of using cheap metaphors which are dangerous in the context of quantum mechanics where they provide a deceiving impression of depth and understanding. In this book, you actually learn something. Sure you do not become an expert in foundations, but you get an accurate sense of what motivates researchers in the field. This is both nice in itself, and if you want to keep on digging with a more specialized book. Even though I already knew the technical content of the book, I found the inquiry captivating. I definitely recommend Through two doors at once, especially to my friends and family who want to quickly yet genuinely understand the sorts of questions that drive me.


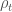 from a noisy continuous measurement readout
from a noisy continuous measurement readout 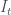 . People often make the confusing remark that the quantum trajectory
. People often make the confusing remark that the quantum trajectory  and then check that the statistics obtained do match the theoretical prediction from continuous measurement theory. Nonetheless there is a valid point which is that this is inconvenient and that to validate the model or measure its parameters, it would be more convenient to talk only about the statistics of the continuous measurement readout. So instead of using the theory to reconstruct the state
and then check that the statistics obtained do match the theoretical prediction from continuous measurement theory. Nonetheless there is a valid point which is that this is inconvenient and that to validate the model or measure its parameters, it would be more convenient to talk only about the statistics of the continuous measurement readout. So instead of using the theory to reconstruct the state 



 ). Additionally, when preliminary searches do not reach this stringent threshold, experimentalists usually provide the statistical significance of their results corrected for the “look elsewhere effect”, that is from the fact that they have explored many hypothesis. This does not mean that physicists never get excited by statistical flukes (see e.g.
). Additionally, when preliminary searches do not reach this stringent threshold, experimentalists usually provide the statistical significance of their results corrected for the “look elsewhere effect”, that is from the fact that they have explored many hypothesis. This does not mean that physicists never get excited by statistical flukes (see e.g.